For remote access, you will need to configure JMX remote passwords and access profiles. Create the files: $HBASE_HOME/conf/jmxremote.passwd (set permissions to 600)
Full Answer
How do I enable HBase in a cluster?
Go to Clusters and select the HBase cluster. Select Configuration. Search for HBase Secure Authorization and select it. Search for HBase Service Advanced Configuration Snippet (Safety Valve) for hbase-site.xml and enter the following into it to enable hbase.security.exec.permission.checks.
Where can I find the HBase configuration file?
Inside the conf folder, you will find several files, open the hbase-site.xml file as shown below. #cd /usr/local/HBase/ #cd conf # gedit hbase-site.xml Inside the hbase-site.xml file, you will find the <configuration> and </configuration> tags.
How do I use HBase authorization?
You have to enable HBase authorization (as detailed in Enable HBase Authorization) to use any kind of authorization method. HBase access levels are granted independently of each other and allow for different types of operations at a given scope. Create (C) - can create tables or drop tables (even those they did not create) at the given scope
How to connect to zookeeper with hbasehost?
For hBaseHost and zookeeperHost I simply pass the ip address of a cluster computer that has zookeeper installed. Of course you can parametize the port numbers too. I am not 100% sure this is the best way to ensure a successful connection but so far it works without any issues. Show activity on this post.
How do I connect to HBase server?
ProcedureProvide Hadoop Identity. ... Provide HBase Identity. ... The path to the core-site. ... Select Authentication method. ... In the HBase Namespace and Target table, specify the table name to which you want to connect and namespace in which it is created (if different than the default namespace).
How do I set up HBase?
How to setup HBase?Install Zookeeper. Firstly we need a zookeeper. ... Get the zookeeper data directory. Now that we have a zookeeper downloaded and installed, we need to look for the zoo. ... Download HBase. Once we have the zookeeper set, you can move on to download HBase. ... Edit HBase Configurations. ... Start HBase.
How do I access my HBase database?
Follow the steps given below to retrieve data from the HBase table.Step 1: Instantiate the Configuration Class. ... Step 2: Instantiate the HTable Class. ... Step 3: Instantiate the Get Class. ... Step 4: Read the Data. ... Step 5: Get the Result. ... Step 6: Reading Values from the Result Instance.
How do I access HBase table?
To access the HBase shell, you have to navigate to the HBase home folder. You can start the HBase interactive shell using “hbase shell” command as shown below. If you have successfully installed HBase in your system, then it gives you the HBase shell prompt as shown below.
Can HBase run without Hadoop?
HBase can be used without Hadoop. Running HBase in standalone mode will use the local file system. Hadoop is just a distributed file system with redundancy and the ability to scale to very large sizes.
Can HBase run without zookeeper?
HBase relies completely on Zookeeper. HBase provides you the option to use its built-in Zookeeper which will get started whenever you start HBAse. But it is not good if you are working on a production cluster.
Why should I use HBase?
HBase is an ideal big data solution if the application requires random read or random write operations or both. If the application requires to access some data in real-time then it can be stored in a NoSQL database. HBase has its own set of wonderful API's that can be used to pull or push data.
What is TTL in HBase?
ColumnFamilies can set a TTL length in seconds, and HBase will automatically delete rows once the expiration time is reached. This applies to all versions of a row - even the current one. The TTL time encoded in the HBase for the row is specified in UTC.
How do you query HBase?
To query HBase data:Connect the data source to Drill using the HBase storage plugin. ... Determine the encoding of the HBase data you want to query. ... Based on the encoding type of the data, use the “CONVERT_TO and CONVERT_FROM data types” to convert HBase binary representations to an SQL type as you query the data.
How do I join two tables in HBase?
Using Hive or Impala is costly when data is to large and we face issue like Hbase kill(region server Down) . so it is convenient when data is small but not for large Data. In mapreduce take Hbase table object to take one table and by extending tablemapper use 2nd table. By this way you can join 2 tables.
How does Apache HBase work?
How does HBase work? HBase is a column-oriented, non-relational database. This means that data is stored in individual columns, and indexed by a unique row key. This architecture allows for rapid retrieval of individual rows and columns and efficient scans over individual columns within a table.
How do I start-HBase master service?
Start the cluster by running the start-hbase.sh command on node-1. ZooKeeper starts first, followed by the Master, then the RegionServers, and finally the backup Masters. Run the jps command on each node to verify that the correct processes are running on each server.
How do I run HBase on Windows?
HBase Installation Steps:Unzip the downloaded Hbase and place it in some common path, say C:/Document/hbase-2.2.5.Create a folders as shown below inside root folder for HBase data and zookeeper. ... Open C:/Document/hbase-2.2.5/bin/hbase.cmd in notepad++. ... Open C:/Document/hbase-2.2. ... Open C:/Document/hbase-2.2.More items...•
How do I start-HBase in Windows?
Run start-hbase.cmdOpen command prompt and cd to HBase' bin directory.Run hbase shell [should connect to the HBase server]Try creating a table.create 'emp','p'list [Table name should get printed]put 'emp','emp01','p:fn','First Name'scan 'emp' [The row content should get printed]
How do I know if HBase is installed?
Start and test your HBase clusterUse the jps command to ensure that HBase is not running.Kill HMaster, HRegionServer, and HQuorumPeer processes, if they are running.Start the cluster by running the start-hbase.sh command on node-1.More items...
What is HBase used for?
HBase is most effectively used to store non-relational data, accessed via the HBase API. Apache Phoenix is commonly used as a SQL layer on top of HBase allowing you to use familiar SQL syntax to insert, delete, and query data stored in HBase.
How to get stable version of hbase?
Download the latest stable version of HBase form http://www.interior-dsgn.com/apache/hbase/stable/ using “wget” command, and extract it using the tar “zxvf” command. See the following command.
How many servers can you start with HBase?
Using the “local-master-backup.sh” you can start up to 10 servers. Open the home folder of HBase, master and execute the following command to start it.
What is a Hadoop site.xml file?
The hdfs-site.xml file contains information such as the value of replication data, namenode path, and datanode path of your local file systems, where you want to store the Hadoop infrastructure.
What is core site xml?
The core-site.xml file contains information such as the port number used for Hadoop instance, memory allocated for file system, memory limit for storing data, and the size of Read/Write buffers.
Why is SSH required in Hadoop?
SSH setup is required to perform different operations on the cluster such as start, stop, and distributed daemon shell operations. To authenticate different users of Hadoop, it is required to provide public/private key pair for a Hadoop user and share it with different users.
What is the default port number for Hadoop?
The default port number to access Hadoop is 50070. Use the following url to get Hadoop services on your browser.
Where are the configuration files in Hadoop?
You can find all the Hadoop configuration files in the location “$HADOOP_HOME/etc/hadoop”. You need to make changes in those configuration files according to your Hadoop infrastructure.
The Big Picture
There are two sets of IP addresses to think about when setting up FileMaker Server to allow remote clients to login.
Click on the Network Info item on the left sidebar
The IP address of will be displayed under the Built-in Ethernet, or Airport Network, whichever is in use by server computer.
Choose the Make and Model of the Router
Select a Manufacturer and then the router model in the popup list. Click ‘Search’ for the detailed view of the model.
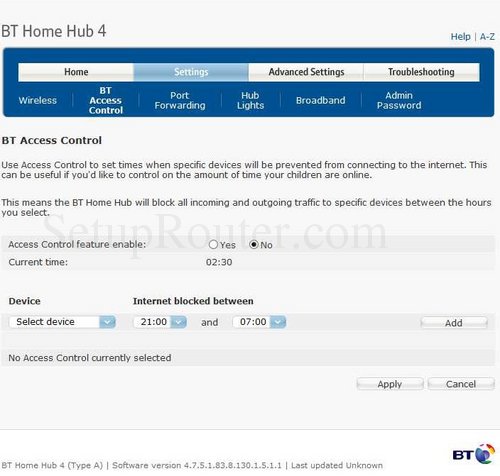
FileMaker Port setups
Port 5003 is fairly standard for FileMaker Server sharing, but portforward.com has a separate manual for each most versions of FileMaker Pro and FileMaker Server
Detailed setup manual for FileMaker Server
There is a detailed description of setting up port forwarding for FileMaker Pro or FileMaker Server for each model of router listed.
Sample Entry for a Linkys Router, FileMaker Server
Sample entry of a port forwarding entry in a network router web admin screen.
Setting up Port Forwarding
Now that the two important IP addresses, the Internal IP address and the external IP address have been obtained, it is time to use this information in the setup of the Router.
How to install Remote Access on DirectAccess?
On the DirectAccess server, in the Server Manager console, in the Dashboard, click Add roles and features. Click Next three times to get to the server role selection screen. On the Select Server Roles dialog, select Remote Access, and then click Next.
How to access remote access server?
On the Remote Access server, open the Remote Access Management console: On the Start screen, type, type Remote Access Management Console, and then press ENTER. If the User Account Control dialog box appears, confirm that the action it displays is what you want, and then click Yes.
How to deploy DirectAccess for remote management only?
In the DirectAccess Client Setup Wizard, on the Deployment Scenario page , click Deploy DirectAccess for remote management only, and then click Next.
How to add roles and features to DirectAccess?
On the DirectAccess server, in the Server Manager console, in the Dashboard, click Add roles and features.
What group does DirectAccess belong to?
For a client computer to be provisioned to use DirectAccess, it must belong to the selected security group . After DirectAccess is configured, client computers in the security group are provisioned to receive the DirectAccess Group Policy Objects (GPOs) for remote management.
How to add domain suffix in remote access?
On the DNS Suffix Search List page, the Remote Access server automatically detects domain suffixes in the deployment. Use the Add and Remove buttons to create the list of domain suffixes that you want to use. To add a new domain suffix, in New Suffix, enter the suffix, and then click Add. Click Next.
What is a remote access URL?
A public URL for the Remote Access server to which client computers can connect (the ConnectTo address)
kirillsavine commented on Jun 6, 2017
I have been trying to setup HBase for the first time. I am able to successfully run the native Hbase shell on the server. But I am not able to connect remotely via a client.
Here are last 3 lines from Hbase log
It says that connection from 192.168.0.11 (client IP) is accepted, but immediately after that it throws an Exception causing close of session:
wbolster commented on Jun 6, 2017
seems like you are not connecting to the thrift server, which generally listens on another port.
kirillsavine commented on Jun 6, 2017
Thank you so much for your answer! I just figured I need to use port 9090
What is HBase access level?
HBase access levels are granted independently of each other and allow for different types of operations at a given scope.
What is the combination of access levels and scopes?
The combination of access levels and scopes creates a matrix of possible access levels that can be granted to a user. In a production environment, it is useful to think of access levels in terms of what is needed to do a specific job. The following list describes appropriate access levels for some common types of HBase users. It is important not to grant more access than is required for a given user to perform their required tasks.
What is a namespace admin?
Namespace Admin - a namespace admin with Create permissions can create or drop tables within that namespace, and take and restore snapshots. A namespace admin with Admin permissions can perform operations such as splits or major compactions on tables within that namespace. Prior to CDH 5.4, only global admins could create namespaces. In CDH 5.4, any user with Namespace Create privileges can create namespaces.
How to change ACL in a cell?
This allows for policy evolution along with data. To change an ACL on a specific cell, write an updated cell with new ACL to the precise coordinates of the original. If you have a multi-versioned schema and want to update ACLs on all visible versions, you'll need to write new cells for all visible versions. The application has complete control over policy evolution. The exception is append and increment processing. Appends and increments can carry an ACL in the operation. If one is included in the operation, then it will be applied to the result of the append or increment. Otherwise, the ACL of the existing cell being appended to or incremented is preserved.
Can Global Admin with Create permissions perform a Put operation on the ACL table?
Also be aware that a Global Admin with Create permission can perform a Put operation on the ACL table, simulating a grant or revoke and circumventing the authorization check for Global Admin permissions. This issue (but not the first one) is fixed in CDH 5.3 and higher, as well as CDH 5.2.1.
Do you need superusers in HBase?
It is important not to grant more access than is required for a given user to perform their required tasks. Superusers - In a production system, only the HBase user should have superuser access. In a development environment, an administrator might need superuser access to quickly control and manage the cluster.
Do ACLs work in HBase?
Unless you modify the default properties as specified (or via the service-wide HBase Service Advanced Configuration Snippet (Safety Valve) for hbase-site.xml, which requires a service restart), then cell level ACLs will not work.
How to enable JMX in HBase?
To enable JMX support in HBase, first edit $HBASE_HOME/conf/hadoop-metrics.properties to support metrics refreshing. (If you've running 0.94.1 and above, or have already configured hadoop-metrics.properties for another output context, you can skip this step).
How to have HBase emit metrics?
To have HBase emit metrics, edit $HBASE_HOME/conf/hadoop-metrics.properties and enable metric 'contexts' per plugin. As of this writing, hadoop supports file and ganglia plugins. Yes, the hbase metrics files is named hadoop-metrics rather than hbase-metrics because currently at least the hadoop metrics system has the properties filename hardcoded. Per metrics context , comment out the NullContext and enable one or more plugins instead.
Why is enabling RPC context good?
Enabling the rpc context is good if you are interested in seeing metrics on each hbase rpc method invocation (counts and time taken).
Can you export HBase metrics?
In addition to the standard output contexts supported by the Hadoop metrics package, you can also export HBase metrics via Java Management Extensions (JMX). This will allow viewing HBase stats in JConsole or any other JMX client.